Imagine sitting in a crowded lecture hall. You naturally tune into the professor’s key points while filtering out side conversations. Attention mechanisms in AI work similarly, selectively focusing on the most relevant parts of input data to make smarter predictions.
💡 Why It Matters:
Attention mechanisms are foundational to modern AI, especially in NLP, image processing, and real-time analytics. They are essential for professionals working with AI integration, model optimization, or enterprise AI solutions, as they empower models to prioritize critical data, making them more adaptive and efficient.
By enabling AI models to focus on the most salient features within complex datasets, attention mechanisms significantly enhance performance, allowing models to handle intricate information more effectively
🚀 How It Works:
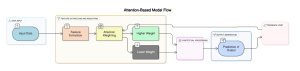
Instead of processing all input data equally, the model assigns weights to different parts.
- Higher weight = More focus.
- This prioritization helps the model concentrate on what’s truly important for the task.
Different types of attention:
- Self-Attention: Finding relationships within the same dataset.
- Cross-Attention: Linking information between different data sets.
- Spatial Attention: Focusing on specific regions within visual data.
| Section Title | Why It Fits | What to Include (Quick Bullets) |
| 1. A 60‑Second Timeline of Attention | Bridges your “How It Works” intro with historical context. | • 2014 — Bahdanau RNN• 2016 — Show‑Attend‑Tell (vision)• 2017 — Transformer breakthrough• 2020 — Vision Transformer (ViT)Add a horizontal graphic for instant visual impact. |
| 2. Anatomy of an Attention Score | Expands the “Higher weight = More focus” idea. | • Query, Key, Value definitions• Softmax equation• Mini diagram of weights turning into a context vector |
| 3. Performance Gains at a Glance (Mini Chart) | Gives evidence for your “enhance performance” claim. | • Bar chart: baseline CNN vs. CNN + spatial attention on ImageNet• BLEU score jump with vs. without attention in translationReaders love quick numbers. |
| 4. Common Pitfalls & How to Avoid Them | Adds practical value for engineers. | • Over‑fitting on small data• Quadratic memory cost for long sequences• Tips: sparse attention, caching, mixed precision |
| 5. Attention in the Wild: A 150‑Word Case Study | Makes the abstract real. | • e.g., E‑commerce search engine boosted CTR + 8% by adding cross‑attention between user query and product listings |
| 6. Ethical & Interpretability Notes | Complements your “Key Insight” on cognitive focus. | • Attention heatmaps ≠ definitive explanations• Risk of focusing on biased tokens• Tools: Captum, AllenNLP Interpret |
| 7. What’s Next? Future Trends & Research Leads | Leaves readers with forward‑looking takeaways. | • Linear & efficient attention (Performer, Flash‑Attention)• Cross‑modal attention for vision‑language models• Edge‑optimized attention for on‑device AI |
🌟 Real-World Applications:
- Image Recognition: Models focus on key objects, improving detection accuracy.
- Speech Recognition: Prioritizes essential audio segments for clearer transcriptions.
- Machine Translation: Aligns corresponding words across languages for fluent output.
🛠 Popular Tools:
- TensorFlow & PyTorch: Both offer built-in attention modules.
- Hugging Face Transformers: Supports models with advanced attention mechanisms.
- Applications: BERT, GPT, Vision Transformers (ViT)
💡 Key Insight: Attention mechanisms mimic human cognitive focus, allowing AI to process complex inputs selectively, leading to smarter, more efficient models
Conclusion
Transformers put attention on the map, but the map is bigger than one city. Whether you’re compressing a mobile vision model, building a streaming ASR engine, or mining knowledge graphs, attention mechanisms give you laser focus without the Transformer overhead. Next time you prototype, ask: “Do I need the whole Transformer, or just a smart spotlight?”
FAQs
Did attention start with Transformers?
No—Bahdanau et al. introduced it in 2014 for RNN translation.
Can I add attention to a CNN?
Yes, SE, CBAM, and similar blocks are drop‑in modules.
Is attention always a quadratic cost?
Only full self‑attention; monotonic, sparse, and linear variants cut it down.
Do graphs need Transformers?
Graph Attention Networks handle edges directly—better for topology.
Will attention replace convolutions?
Likely not; the future is hybrid, mixing the strengths of both.